第3章 站长工具批量查询


课程学习
共8篇
3-1 多个网站查询的痛点
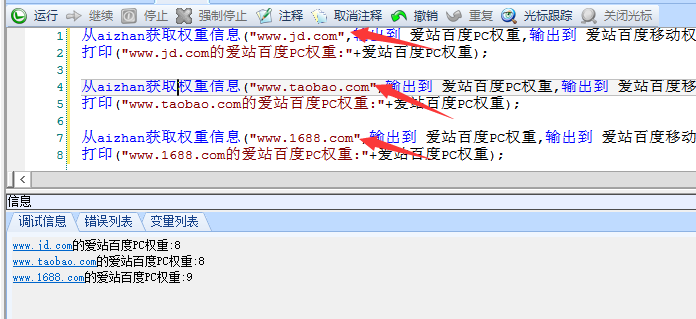
上一章中,我们讲到了如何从爱站、china和搜狗中自动收集指定网站的权重和相关信息,这对我们日常工作带来了极大的便利,我们不再需要每天打开多个站长网站,手动查询网站上权重和其他各类信息。 ,但对于拥有多个网站的朋友似乎有点不友好,要分几次的把网址放入积木中去查询太过繁琐,有多少个网站,就复制积木查询多少次,少量的时候未尝不是个办法,但是当你拥有100或者10000个网站需要检测的时候,你会发现这种方法非常吃力,我必须复制100次甚至10000次积木才能完成我要的工作,如下图:我们要查询三个网站的权重
3-2 站长积木给出解决方案——第一步、新增要查询的两行文本文件
接下来我们就来讲讲如何利用积木读取文本文件的方法来解决多个网站同时查询这个问题。
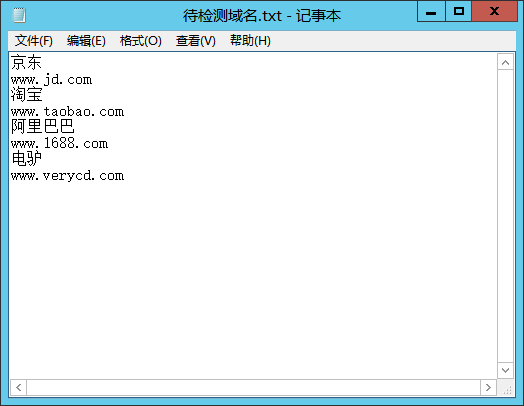
首先,我们在本地存放课程文件同目录下建立一个“待检测域名.txt”的文本文件,如左图所示:
第一行保存着网站的名称,第二行保存着网站的域名。
第一行保存着网站的名称,第二行保存着网站的域名。
京东
www.jdcom
淘宝
www.taobao.com
阿里巴巴
www.1688.com
电驴
www.verycd.com3-3 站长积木给出解决方案——第二部、站长积木如何读取文本文件?
站长积木如何读取文本文件的内容呢,敲黑板划重点清睁大眼睛记好小本本观看
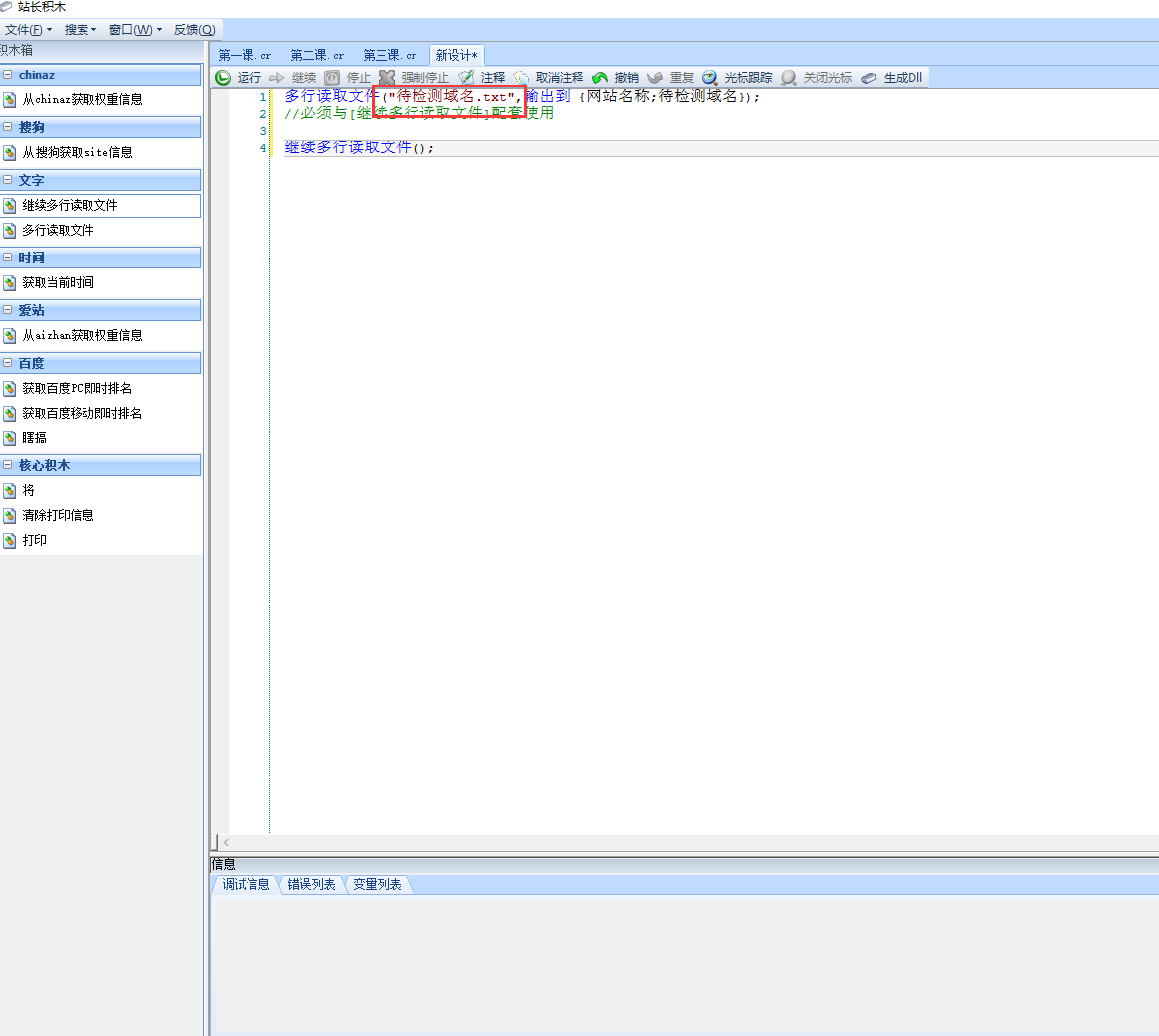

现在我们打开站长积木,拖拽两块积木,“多行读取文件”积木和“继续多行读取文件”积木,左图1:
c:\设计\1.txt,那么就必须设置为 c:\\设计\\1.txt
e:\站长积木教程\待检测域名.txt ,那么就必须是e:\\站长积木教程\\待检测域名.txt,如图2:
多行读取文件(文本文件路径,输出到 {输出到名字1;输出到名字2...});
//必须与[继续多行读取文件]配套使用
继续多行读取文件();多行读取文件("待检测域名.txt",输出到 {网站名称;待检测域名});
//必须与[继续多行读取文件]配套使用
继续多行读取文件();c:\设计\1.txt,那么就必须设置为 c:\\设计\\1.txt
e:\站长积木教程\待检测域名.txt ,那么就必须是e:\\站长积木教程\\待检测域名.txt,如图2:
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
继续多行读取文件();3-4 站长积木给出解决方案——第三步、读取到的文本内容如何使用?
把文本内容一次性读取出来,逐条逐条这样去批量去完成查询任务
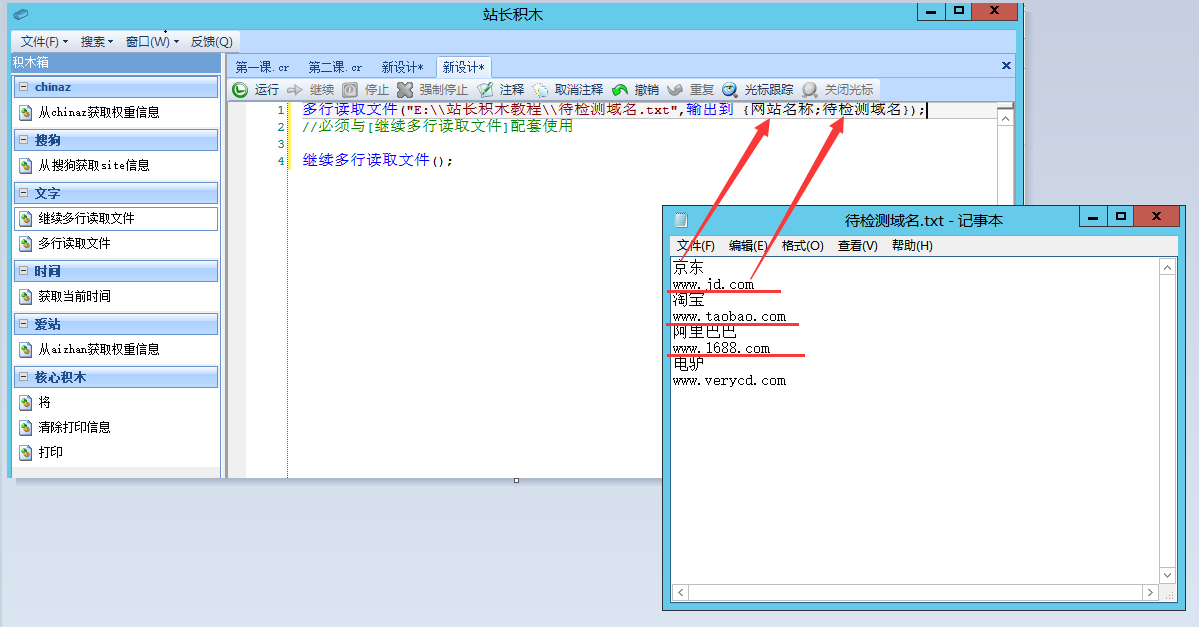
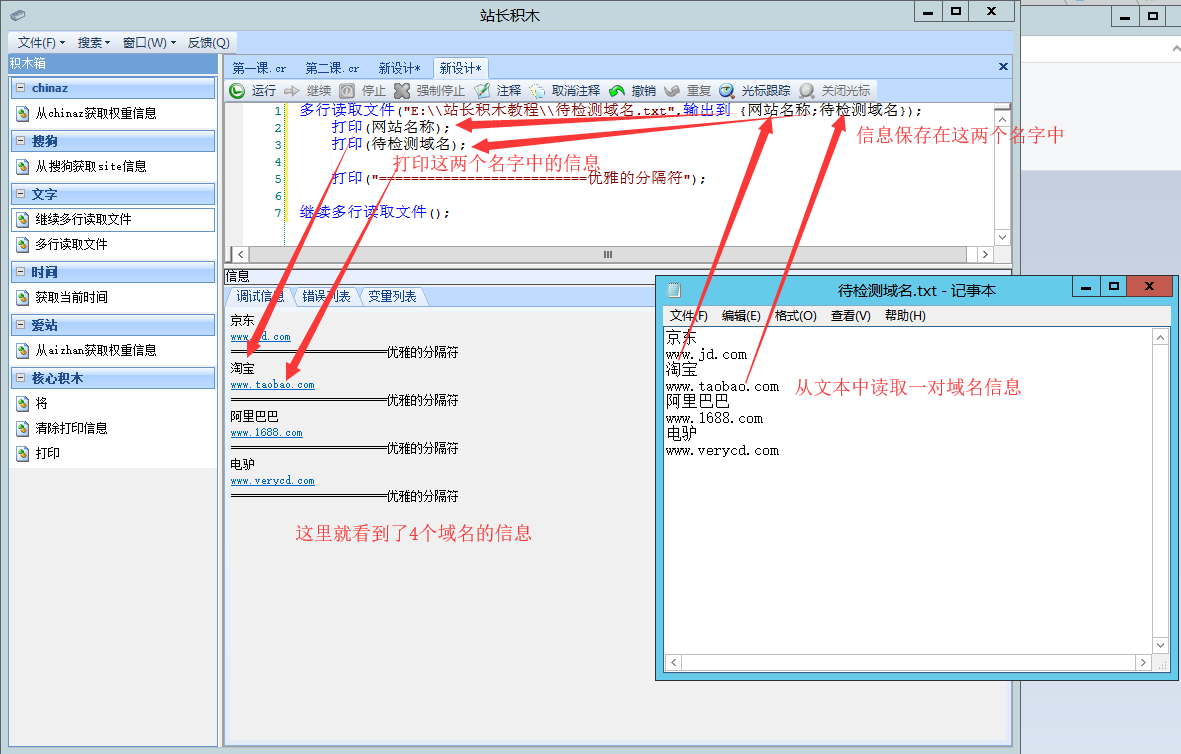
我们以文本文件在目录"E:\\站长积木教程\\待检测域名.txt"为例,我们看到例子中的待检测域名有4个,京东、淘宝、阿里巴巴、电驴,我们需要告诉站长积木,文本中的内容怎么输出并保存起来。左图1:
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
继续多行读取文件();多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
打印("==========================优雅的分隔符");
继续多行读取文件();3-5 站长积木给出解决方案——第四步、实现批量查询?
通过批量读取文本中的信息,实现批量查询效果,从此登上人生巅峰
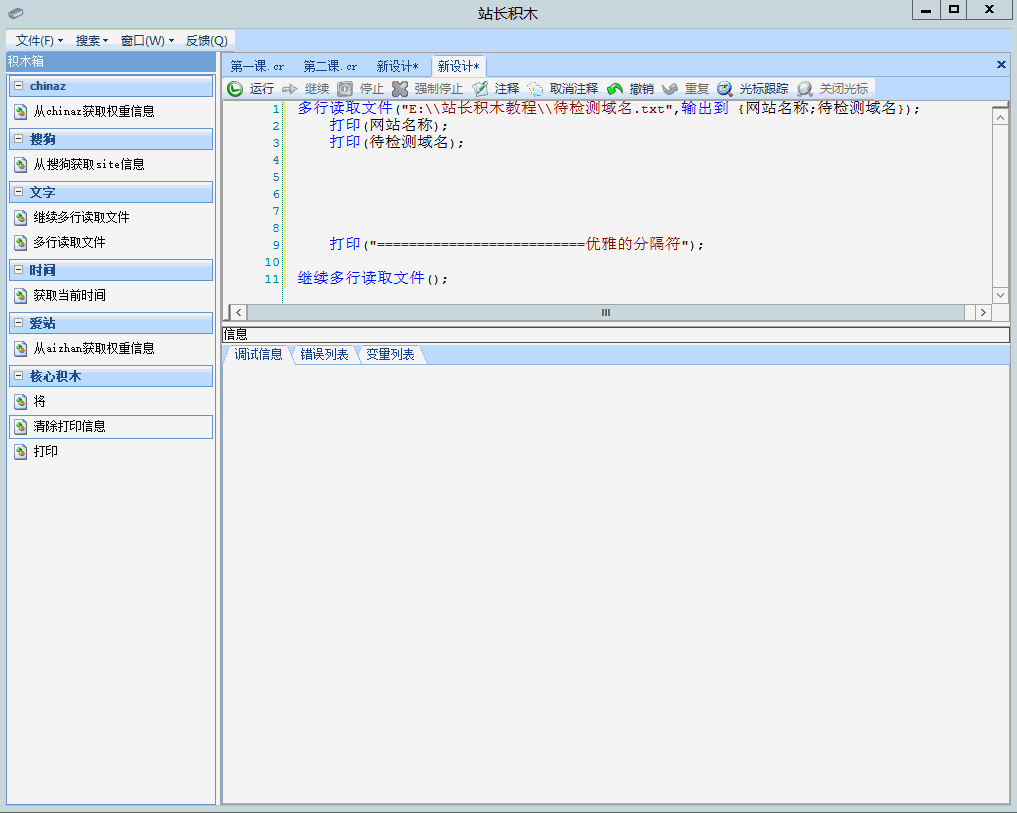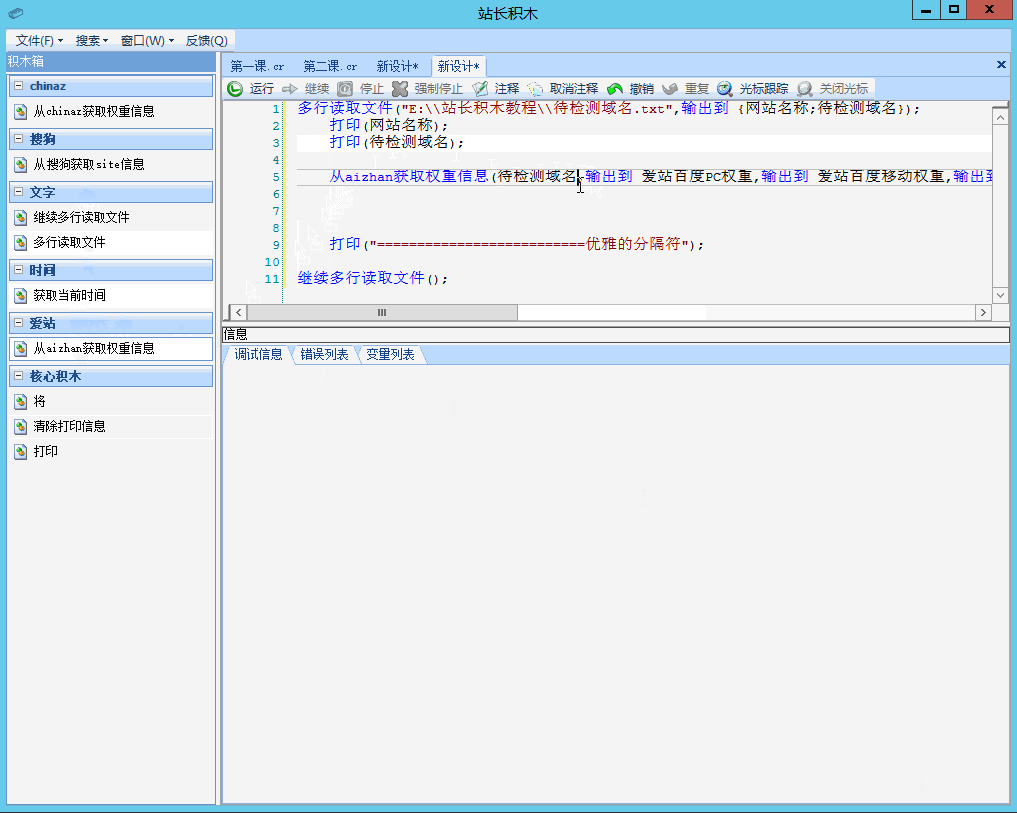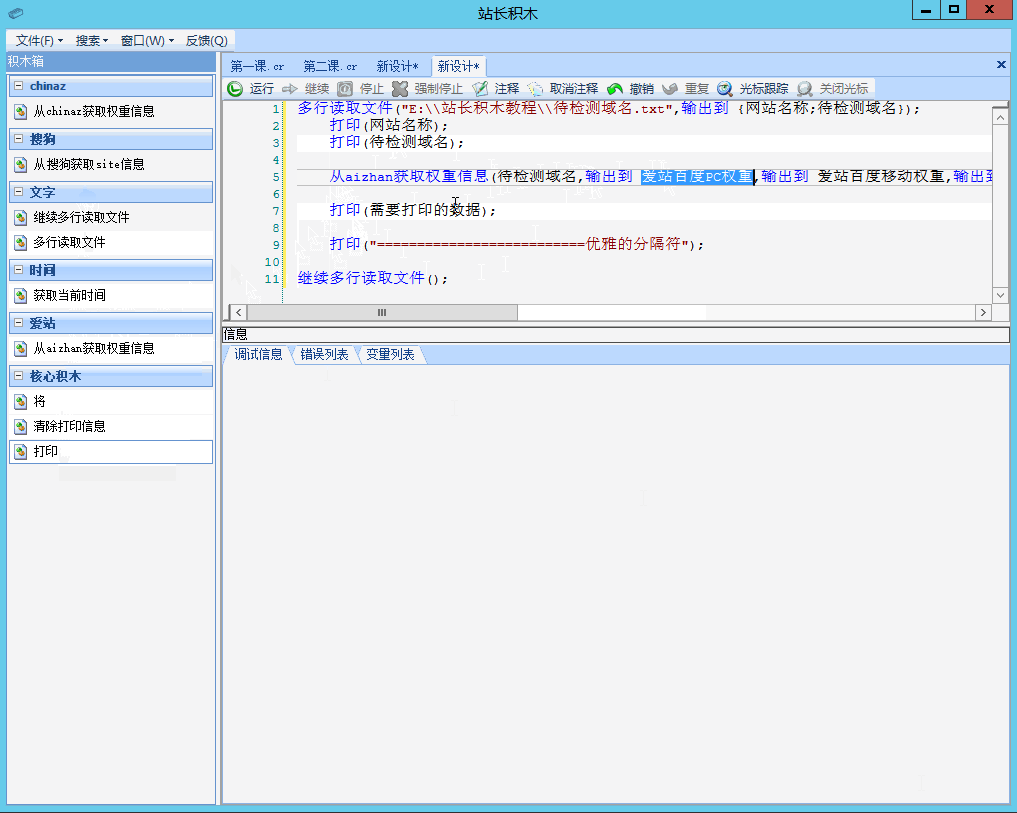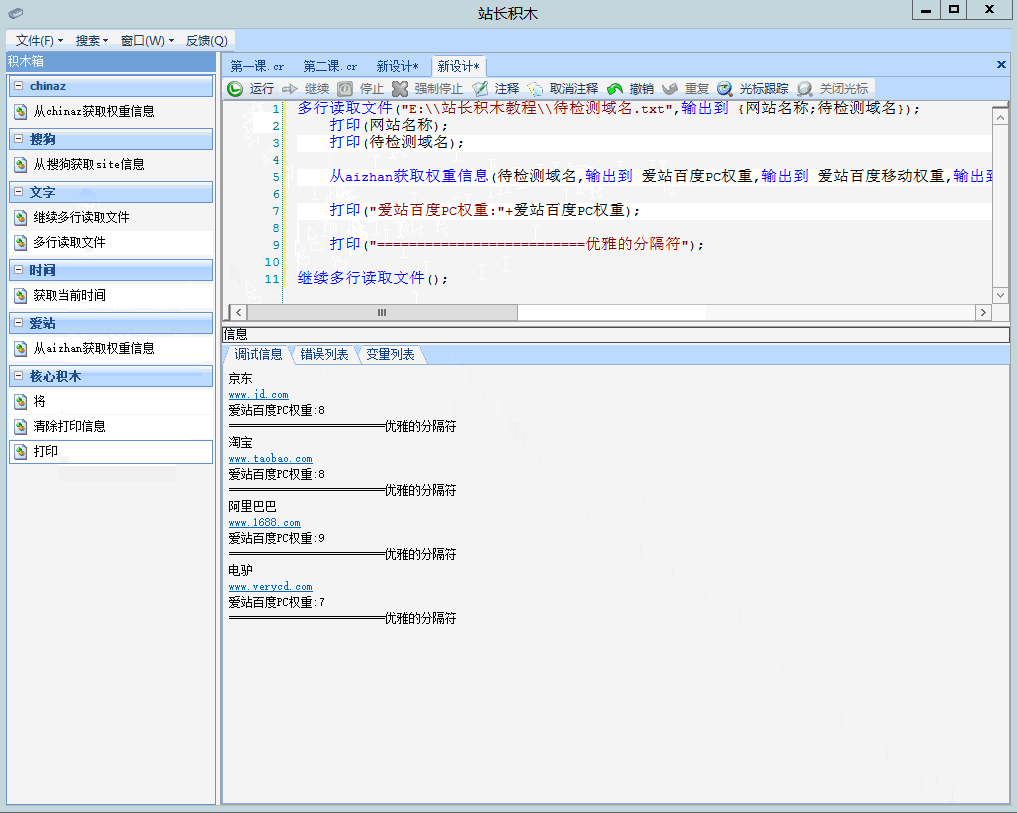
接下来见证奇迹的时刻,我们将第一章中学习到的知识贯穿进来,将获取爱站权重信息的积木插入到其中,效果如左图1:
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
从aizhan获取权重信息(待检测域名,输出到 爱站百度PC权重,输出到 爱站百度移动权重,输出到 爱站外链数,输出到 爱站备案号,输出到 爱站公司类型,输出到 爱站公司名称,输出到 爱站备案时间,输出到 爱站域名年龄,输出到 爱站域名创建时间);
打印("爱站百度PC权重:"+爱站百度PC权重);
打印("==========================优雅的分隔符");
继续多行读取文件();京东
www.jd.com
爱站百度PC权重:8
==========================优雅的分隔符
淘宝
www.taobao.com
爱站百度PC权重:8
==========================优雅的分隔符
阿里巴巴
www.1688.com
爱站百度PC权重:9
==========================优雅的分隔符
电驴
www.verycd.com
爱站百度PC权重:7
==========================优雅的分隔符3-6 本章补充知识点——避免文本文件的错误写入
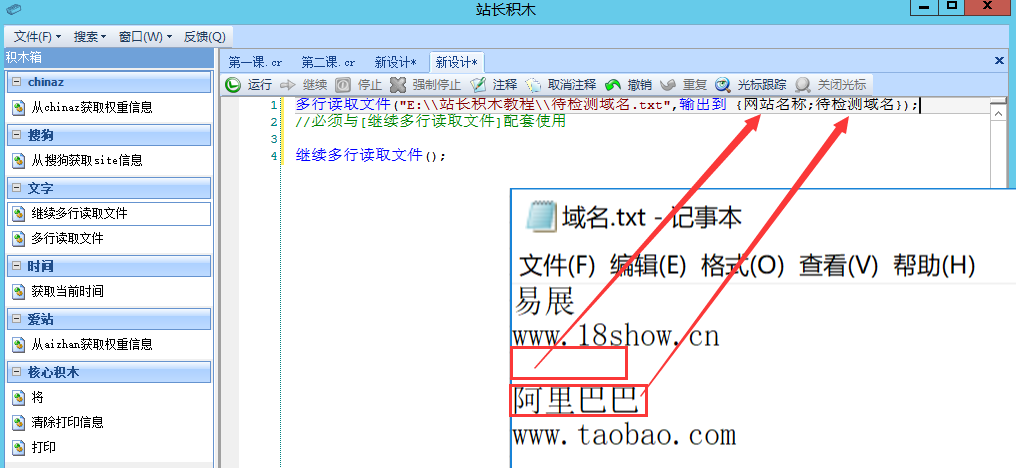
在文本中请不要留空行,这样将会导致出错,例如下图的情况,积木将会把这个空行当作了有效行,而空行下面的“阿里巴巴”当作第二行域名行,这样就全乱了,因为空行也是会被读取输出的

3-7 本章补充知识点——多行读取文件的使用与注意事项
多行读取文件是如何工作的呢?又有哪些问题在使用中容易出现呢?
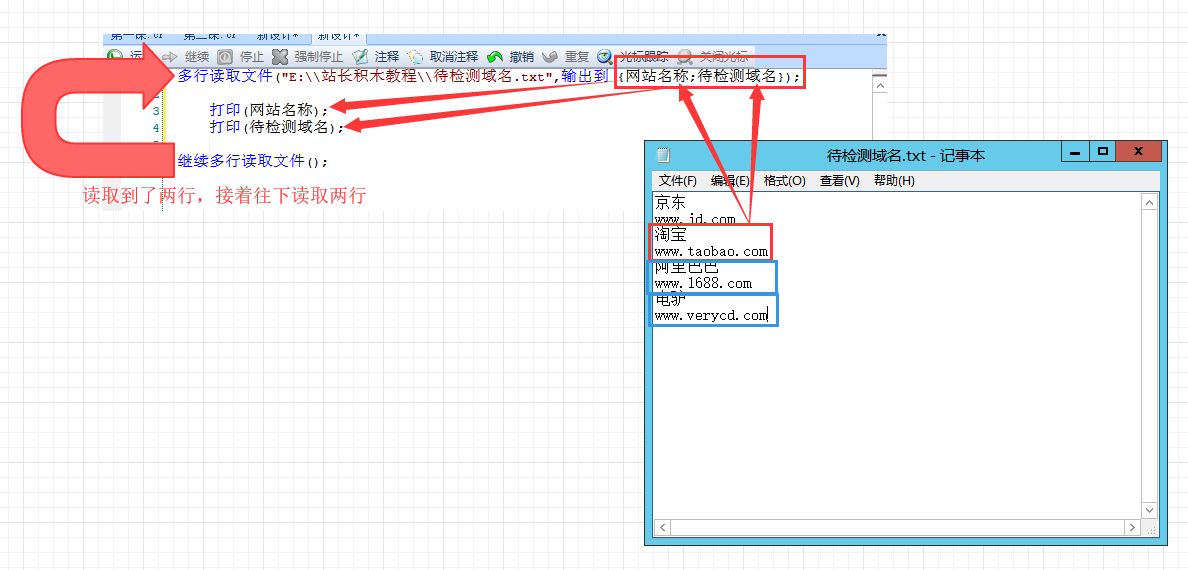
可能对于没有循环概念的朋友还是有点困惑,为什么就能批量处理4个域名呢?我用一副图片来让大家有更直观的认识,左图1:
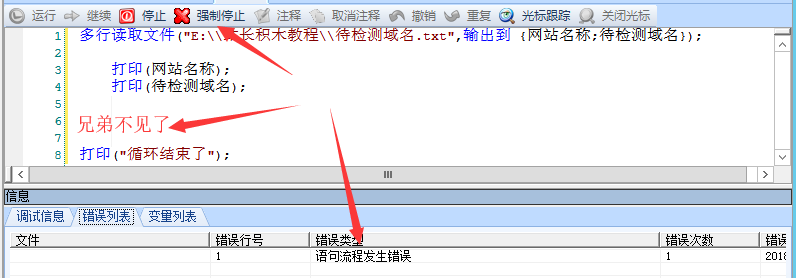
“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
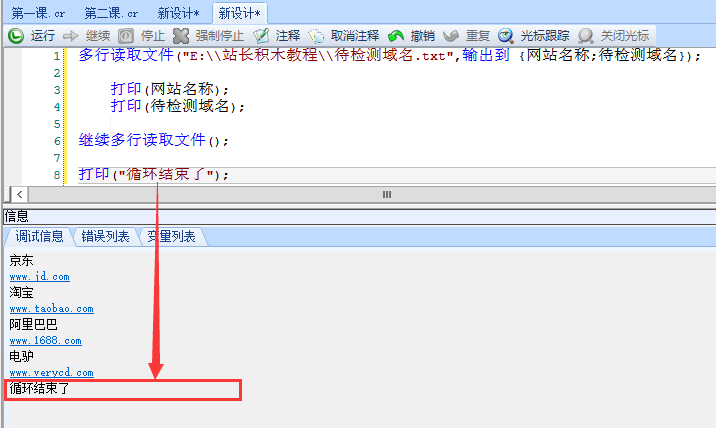
重要的事情再次说三遍,你也可以试试将这两个兄弟分开,那么站长积木一定会报错,这个时候你就只能用强制停止来结束了,左图3:
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
继续多行读取文件();多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
继续多行读取文件();
打印("循环结束了");“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
“多行读取文件”,“继续多行读取文件”两块积木是不可分割的积木兄弟
重要的事情再次说三遍,你也可以试试将这两个兄弟分开,那么站长积木一定会报错,这个时候你就只能用强制停止来结束了,左图3:
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
打印("循环结束了");3-8 本章补充知识点——文本文件行数自定义
“多行读取文件”积木中,如何自由实现文本行数的读取呢?如果我想只读一行,或者多行呢?
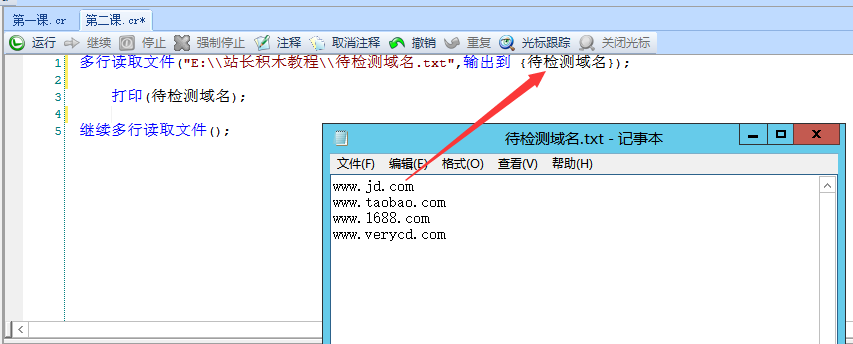
当我们需要一行一行这样读取文本时如何实现呢?左图1:
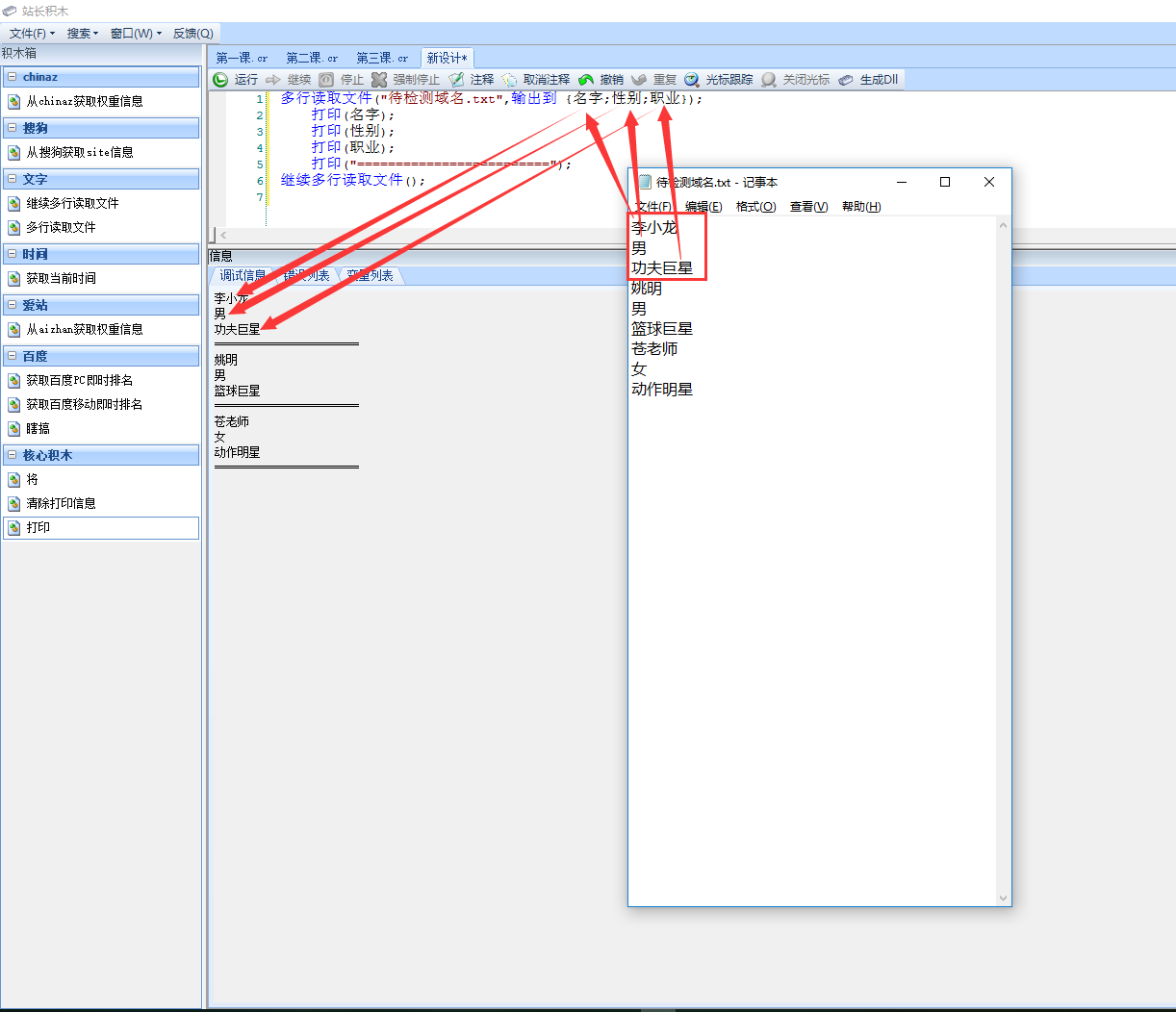
文件内容以每三行为一个单位,“多行读取文件”积木输出名字自定义,输出名称是可以随意修改的,执行效果如图3:
如果我们要执行更多行数大家自行补脑
多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {待检测域名});
打印(待检测域名);
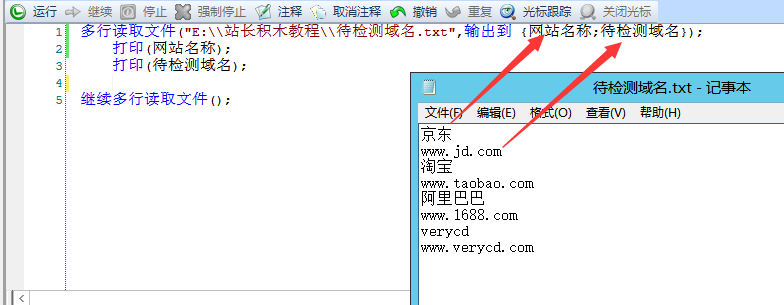
继续多行读取文件();多行读取文件("E:\\站长积木教程\\待检测域名.txt",输出到 {网站名称;待检测域名});
打印(网站名称);
打印(待检测域名);
继续多行读取文件();文件内容以每三行为一个单位,“多行读取文件”积木输出名字自定义,输出名称是可以随意修改的,执行效果如图3:
如果我们要执行更多行数大家自行补脑
多行读取文件("待检测域名.txt",输出到 {名字;性别;职业});
打印(名字);
打印(性别);
打印(职业);
打印("=========================");
继续多行读取文件();